

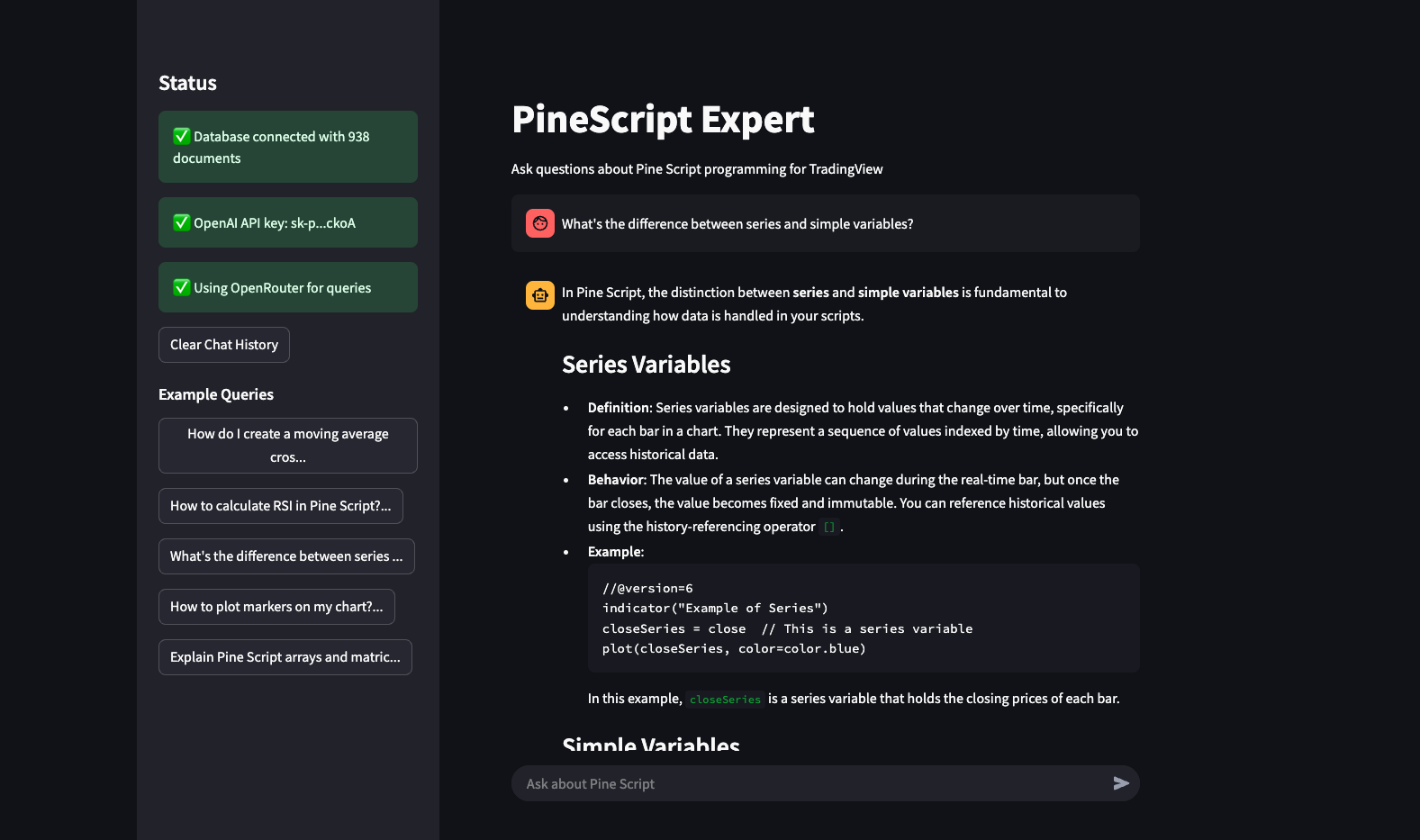
A Retrieval-Augmented Generation (RAG) AI Agent built with Pydantic AI that serves as an expert on Pine Script v6, TradingView's programming language for custom indicators and strategies. This agent leverages vector search technology and large language models to provide accurate, context-aware answers and generate working code examples.
- Comprehensive Pine Script Knowledge: Access the entire Pine Script v6 documentation through natural language queries
- Code Generation: Creates custom indicators and strategies based on user requirements
- Interactive Interfaces: Multiple ways to interact with the expert:
- Web-based UI built with Streamlit
- Interactive command-line interface
- Single query execution for scripting
- Multi-Provider Support: Use either OpenAI or OpenRouter models as the LLM backend
- Vector Search: Utilizes pgvector for efficient semantic retrieval of relevant documentation
- Full Documentation Processing: Custom crawler that processes and analyzes TradingView's Pine Script documentation
- Persistent Chat History: Remember conversation context in the Streamlit UI
- Extensive API: Integrate with other systems using the Pydantic AI based architecture
 |
 |
- Python 3.9+
- PostgreSQL with pgvector extension
- OpenAI API key (required for embeddings and default LLM)
- OpenRouter API key (optional, for alternative LLM providers)
- Docker (optional, for running PostgreSQL with pgvector)
-
Clone the repository
git clone https://github.com/FaustoS88/Pydantic-AI-Pinescript-Expert.git cd pinescript-expert -
Setup PostgreSQL with pgvector using Docker
# Create a directory for Docker volume if it doesn't exist
mkdir -p ~/pinescript_postgres_data
# Run PostgreSQL with pgvector on port 54322 (different from standard 5432)
docker run --name pinescript-pgvector \
-e POSTGRES_PASSWORD=postgres \
-p 54322:5432 \
-v ~/pinescript_postgres_data:/var/lib/postgresql/data \
-d pgvector/pgvector:pg16-
Install requirements and set up the environment
python setup.py # Edit the created .env file with your API keys -
Initialize the database
python init_db.py
-
Populate the database with Pine Script documentation
python pinescript_crawler.py
-
Start using the Streamlit UI
streamlit run streamlit_ui.py
Or, for CLI interface:
python interactive.py
Start the Streamlit interface to interact with the agent through a web UI:
streamlit run streamlit_ui.pyLaunch an interactive shell for conversational access to the agent:
python interactive.pyExample session:
=================================================================
Pine Script Expert Agent - Interactive Shell
=================================================================
Ask any question about Pine Script v6 or type 'exit' to quit.
Type 'clear' to clear the conversation history.
=================================================================
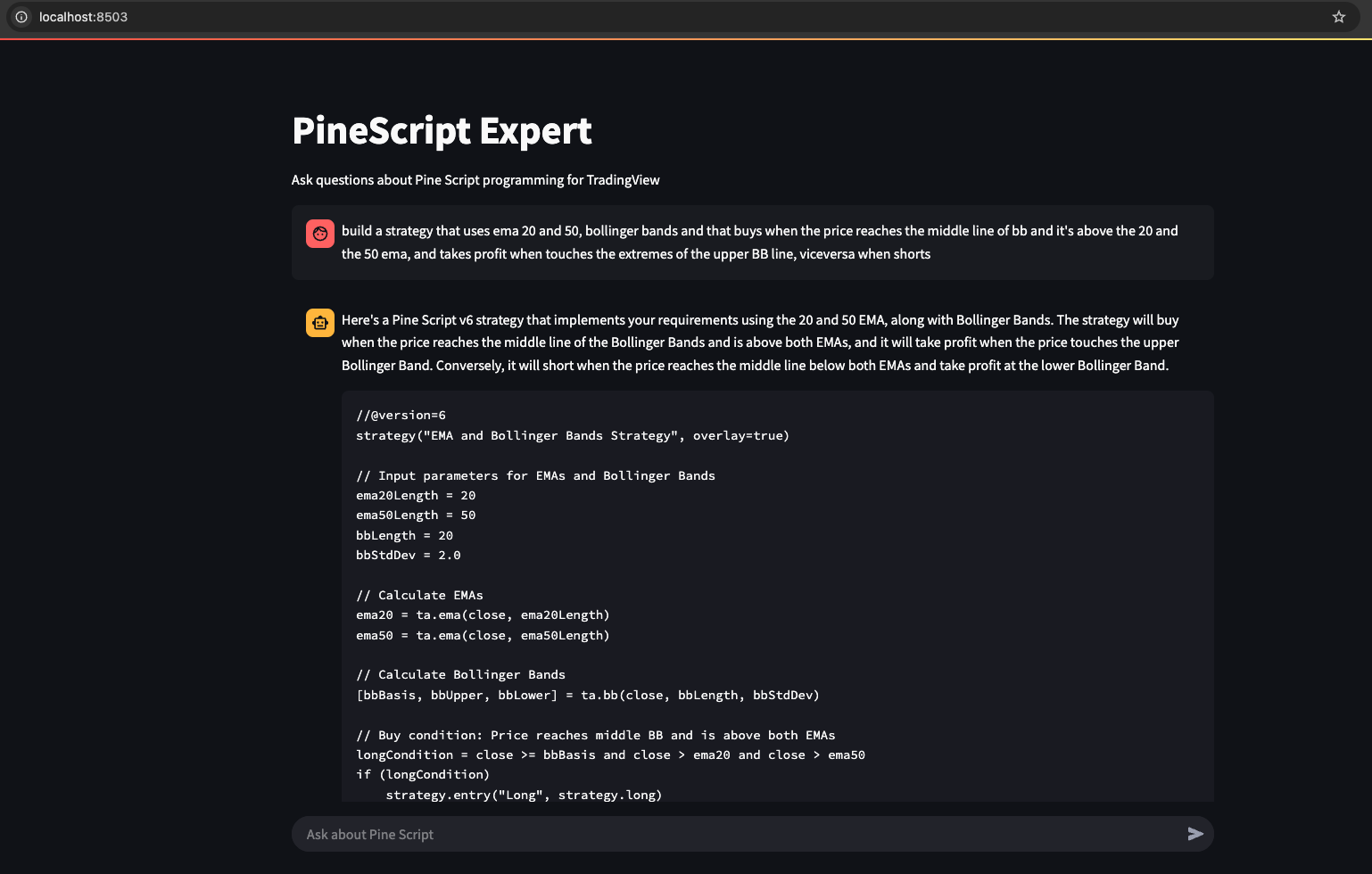
> How do I create a simple moving average crossover strategy?
Processing your question...
================================================================================
To create a simple moving average crossover strategy in Pine Script v6, you'll need to:
1. Set up your indicator or strategy
2. Calculate two moving averages of different lengths
3. Determine crossover conditions
4. Generate buy/sell signals
5. Optionally add plotting for visualization
Here's a complete example:
```pine
//@version=6
strategy("Simple MA Crossover Strategy", overlay=true)
// Input parameters
fastLength = input.int(9, "Fast MA Length")
slowLength = input.int(21, "Slow MA Length")
// Calculate moving averages
fastMA = ta.sma(close, fastLength)
slowMA = ta.sma(close, slowLength)
// Determine crossover conditions
buySignal = ta.crossover(fastMA, slowMA)
sellSignal = ta.crossunder(fastMA, slowMA)
// Execute strategy
if (buySignal)
strategy.entry("Buy", strategy.long)
if (sellSignal)
strategy.entry("Sell", strategy.short)
// Plot moving averages
plot(fastMA, "Fast MA", color=color.blue)
plot(slowMA, "Slow MA", color=color.red)
// Plot buy/sell signals
plotshape(buySignal, "Buy Signal", shape.triangleup, location.belowbar, color.green, size=size.small)
plotshape(sellSignal, "Sell Signal", shape.triangledown, location.abovebar, color.red, size=size.small)
Key components explained:
- We use
ta.sma()to calculate the simple moving averages ta.crossover()andta.crossunder()detect when the fast MA crosses above or below the slow MAstrategy.entry()executes buy and sell orders when crossovers occurplot()andplotshape()visualize the MAs and signals on the chart
You can customize this by changing:
- MA types (SMA, EMA, WMA, etc.)
- Length parameters
- Adding additional conditions
- Adding stop-loss and take-profit levels ================================================================================
### Single Query Mode
Use the agent for a one-time query:
```bash
python run.py query "How do I calculate RSI in Pine Script?"
The project includes tools to inspect the vector database:
# Count documents in the database
python db_inspect.py count
# List document titles (first 20)
python db_inspect.py list
# View a specific document
python db_inspect.py view 508
# Test search functionality
python db_inspect.py search "how to use request.security for different timeframes"The retrieval pipeline has been systematically improved across two tiers and measured with RAGAS (40-question test set, categories: function lookup, conceptual, code generation, complex multi-concept).
| Pipeline | Faithfulness | Context Relevance | vs Baseline |
|---|---|---|---|
| Baseline (flat chunks, L2 search) | 0.779 | n/a | — |
| Tier 1 (hybrid search, MMR, recursive chunking) | 0.774 | — | -0.6% |
| Tier 2 (+ Anthropic Contextual Retrieval) | 0.833 | 0.919 | +6.9% |
Code generation improved from 0.51 → 0.64 (+21%) with Tier 2. Context Relevance 0.919 means the retriever finds the right chunks 92% of the time — the remaining gap is a content problem (docs lack complete strategy templates), not a retrieval problem.
Tier 1 improvements (docs): hybrid BM25+vector search, similarity threshold, cross-encoder reranking, recursive chunking with overlap, MMR deduplication, contextual chunk headers
Tier 2 improvements (docs): code-aware chunking (fenced blocks never split), Anthropic Contextual Retrieval (LLM prefix per chunk at crawl time), content type detection, metadata columns
Evaluation details: Tier 1 | Tier 2
# Tier 1 retrieval (hybrid + MMR)
python tests/ragas_eval.py --retrieval tier1 --output results/tier1_YYYYMMDD.json
# Baseline retrieval (L2 only)
python tests/ragas_eval.py --retrieval baseline --output results/baseline_YYYYMMDD.json# Standard re-crawl (code-aware split, free)
python pinescript_recrawl_light.py --clear
# Contextual re-crawl (LLM prefix per chunk — ~$8, ~2h for 4,910 chunks)
python pinescript_recrawl_light.py --contextual --clearagent.py: Core agent implementation with RAG capabilitiespinescript_crawler.py: Documentation crawler and vector database populationdb_schema.py: Database schema definitionsstreamlit_ui.py: Web-based user interface with persistent chat historyinteractive.py: Command-line interfacerun.py: Convenience runner for various operation modesinit_db.py: Database initializationclear_database.py: Database cleaning utilitydb_inspect.py: Database inspection tools
Switch between LLM providers using the --model flag. Presets are defined in config.py:
| Preset | Model | Temperature | Max Tokens |
|---|---|---|---|
default |
openai/gpt-4.1-mini |
0.2 | 2000 |
codex |
openai/gpt-5.3-codex |
0.1 | 4096 |
opus |
anthropic/claude-opus-4-6 |
0.2 | 4096 |
flash |
google/gemini-3-flash-preview |
0.3 | 2000 |
# Use a preset
python run.py query "How to use request.security?" --model codex
python run.py interactive --model opus
# Or pass any OpenRouter model ID directly
python run.py query "Explain ta.sma()" --model "anthropic/claude-sonnet-4.6"All presets route through OpenRouter — add your API key to .env as OPENROUTER_API_KEY. Without it, the agent falls back to the default OpenAI model.
You can also override defaults via environment variables:
PINESCRIPT_MODEL=openai:gpt-4o # default LLM
PINESCRIPT_TEMPERATURE=0.3 # response creativity
PINESCRIPT_MAX_TOKENS=4096 # max response length
PINESCRIPT_VECTOR_SEARCH_LIMIT=12 # RAG retrieval depth
OPENROUTER_MODEL=anthropic/claude-opus-4-6 # default OpenRouter modelConfigure database settings in the .env file:
DATABASE_URL=postgresql://username:password@hostname:port/database
Contributions are welcome!
This project is licensed under the MIT License - see the LICENSE file for details.
- Pydantic AI for the agent framework
- TradingView for the Pine Script language and documentation
- OpenAI and OpenRouter for LLM capabilities
- pgvector for vector search functionality
- Streamlit for the web interface